데이터 처리를 할 때 왜 스파크를 써야하는지, 왜 빠른지에 대해 공부하며
의 도움을 많이 받았습니다.
주력언어가 Python인 만큼 Pyspark를 썼으면 하는 바램이 컸지만, Scala에서의 퍼포먼스가 더 좋다는데 왜일까? 왜 Pyspark에서는 Dataset을 지원하지않지?
라는 궁금증들이 생겨 여러 블로그를 뒤져가며 나름 정리 해 봤는데요, 다른 분들께도 도움이 됐으면 좋겠습니다.
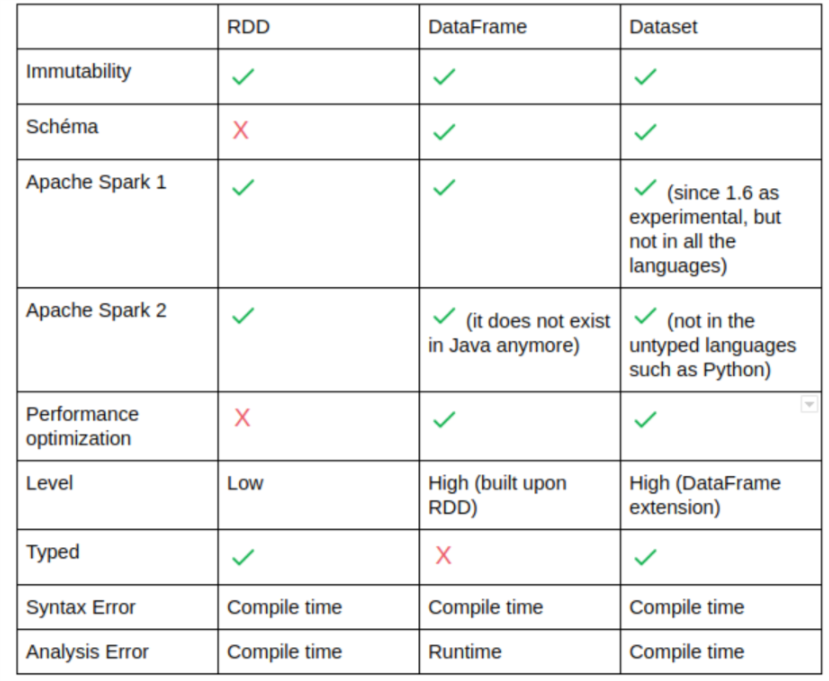
RDD
- Java, Scala의 객체를 처리하는 방식
- 함수를 1) Transformation 2) Action으로 나눠 Action에 해당하는 함수를 호출할 때 실행된다.
- transformation의 결과는 RDD로 생성
- 내부에 데이터 타입이 명시
- 쿼리 최적화등을 지원하지 않았음(카탈리스트 옵티마이저 X)
- Pyspark에서 UDF선언시 인터프리터와 JVM사이 커뮤니케이션으로 속도가 저하됨( Python의 경우 Scala의 2배), 반드시 built in 함수만 쓸 것
DataFrame
- 내부 데이터가 Row라는것만 명시, 실제 데이터 타입은 알 수 없음
- 스키마 추상화
- Python Wrapper코드로 Python에서의 성능이 향상되었다.
- Dataset 제네릭 객체 집합에 대한 별칭
- RDD와 마찬가지로 Pyspark에서 함수를 선언해서 사용할 경우(UDF), 속도 저하의 원인이 될 수 있다.
- 카탈리스트 옵티마이저 지원
Dataset
- 데이터타입이 명시되어야함
- 스키마 추상화
- Scala/Java에서 정의한 클래스에 의해 타입을 명시해야하는 JVM객체. 따라서 Python은 지원하지 않음.
- 카탈리스트 옵티마이저 지원
오개념 또는 출처 명시가 부족하다면, 피드백 부탁드립니다.
좀 더 자세한 내용은 길은가면, 뒤에있다 블로그를 참고하시면 좋을 것 같습니다.
출처